
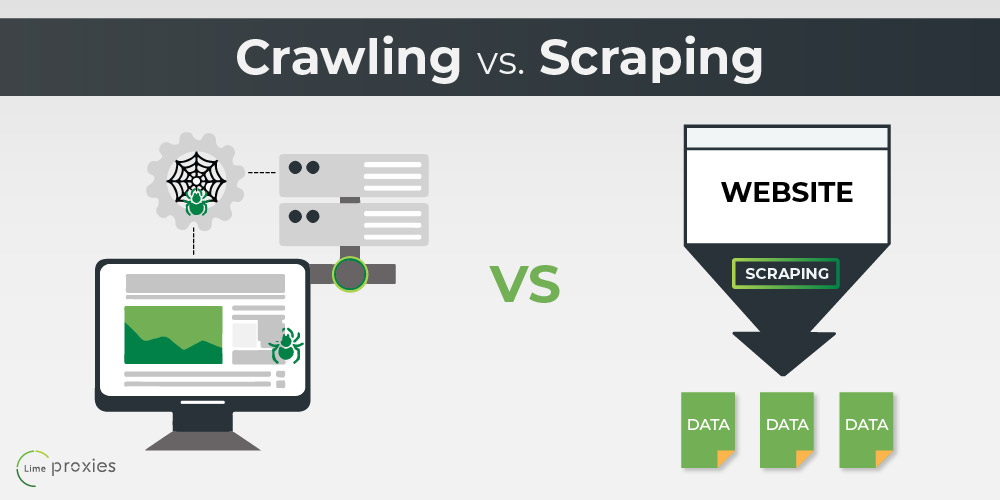
TL;DR — Crawling vs Scraping at a Glance
Last updated: March 2026.
| | Web Crawling | Web Scraping | |---|---|---| | What it does | Discovers and maps URLs | Extracts structured data | | Output | URL list / site map | Structured dataset (CSV, JSON, DB) | | Tools | Scrapy, Nutch, Heritrix | Beautiful Soup, Puppeteer, Playwright | | Scale | Millions of pages | Targeted pages or full sites | | Blocks | Rarely blocked | Frequently blocked | | Proxy need | Yes at scale | Yes, especially for anti-bot sites |
Bottom line: Crawling maps the web; scraping harvests data from it. Most production data pipelines use both.
What Is Web Crawling?
A web crawler (also called a spider or bot) is an automated program that systematically browses the internet by following links from page to page, recording the URLs it discovers. Search engines — Google, Bing, Yandex — use massive crawler fleets to index the entire web.
How a web crawler works:
- Starts with a seed URL (an initial page to begin from)
- Fetches the page and extracts all hyperlinks
- Adds newly discovered URLs to a queue (if not already visited)
- Fetches the next URL in the queue and repeats
- Continues until the queue is empty or a stop condition is met
What crawlers produce:
- Complete URL inventory of a website
- Site structure map (which pages link to which)
- Page metadata (title, description, last modified)
- Content snapshots for indexing
Core Qualities of an Effective Web Crawler
1. Politeness (Rate Limiting)
Responsible crawlers respect robots.txt directives and add delays between requests to avoid overloading target servers. The standard is to honor Crawl-delay settings and never exceed 1 request per second on any single domain without explicit permission.
2. Scalability Enterprise crawlers process millions of URLs per day using distributed worker architectures. Apache Nutch runs across Hadoop clusters; custom Scrapy deployments use Redis or Kafka as distributed URL queues.
3. Intelligent Recrawling Rather than recrawling every page on a fixed schedule, smart crawlers prioritize frequently updated pages (news sites, pricing pages) and reduce crawl frequency for static content (about pages, terms of service).
4. Language and Platform Neutrality Modern crawlers handle HTTP, HTTPS, redirects (301/302), cookie-based sessions, and JavaScript-rendered content (via headless browser integration). They parse HTML, XML, JSON, and structured data formats.
5. Deduplication
URL normalization and content fingerprinting prevent crawlers from processing the same content multiple times through different URL patterns (e.g., ?session=abc vs. ?session=xyz pointing to the same page).
What Is Web Scraping?
Web scraping is the targeted extraction of specific data fields from web pages. While crawling builds a map, scraping harvests the actual content — prices, product names, contact information, reviews, financial data, or any other structured information displayed on a page.
How a Scraper Bot Works
1. Send HTTP request to target URL
↓
2. Receive HTML response
↓
3. Parse HTML with a parser (Beautiful Soup, Cheerio, etc.)
↓
4. Locate target data using CSS selectors or XPath
↓
5. Extract and clean the data
↓
6. Store to database, CSV, or JSON
↓
7. Move to next URL and repeat
For JavaScript-rendered pages, step 1-2 is replaced by a headless browser (Puppeteer/Playwright) that fully renders the page before parsing.
Types of Web Scraping
Content Scraping Extracting articles, product descriptions, reviews, or any textual content. Used by news aggregators, content monitoring services, and market intelligence platforms.
Contact Scraping Extracting email addresses, phone numbers, and business names from directories, LinkedIn, or company websites. Used for lead generation and B2B prospecting. (Note: collecting personal data may have GDPR implications.)
Price Scraping Monitoring competitor pricing, product availability, and promotional changes in real time. Used heavily in e-commerce, travel fare aggregation, and financial data collection. LimeProxies customers use our rotating proxy infrastructure to monitor pricing across thousands of retailer pages simultaneously.
Review and Rating Scraping Collecting customer reviews from Amazon, Google, Yelp, Trustpilot, and similar platforms for sentiment analysis and brand monitoring.
Web Crawling vs Web Scraping: 10 Key Differences
| Dimension | Web Crawling | Web Scraping | |-----------|-------------|-------------| | Primary goal | Discover and index URLs | Extract structured data | | Scope | Broad — entire websites or domains | Narrow — specific pages or data fields | | Output type | URL list, site map | Structured data (CSV, JSON, DB) | | Depth of processing | Shallow (URL + metadata) | Deep (full page parsing) | | Speed | Very fast (millions of URLs/day) | Slower (depends on parsing complexity) | | JavaScript support | Optional | Often required | | Anti-bot impact | Low | High (scrapers are frequently blocked) | | Proxy need | Yes, at scale | Yes, especially for protected targets | | Primary tools | Scrapy, Nutch, Heritrix | BS4, Puppeteer, Playwright, Selenium | | Typical use case | SEO audit, search indexing, site mapping | Price monitoring, lead gen, market research |
How Proxies Enable Scraping and Crawling at Scale
Both web crawling and scraping at scale require rotating IP addresses. Without proxies, your server IP will be rate-limited or permanently blocked by target sites after a small number of requests.
Why IPs Get Blocked
Sites detect automated traffic through:
- Request frequency: More than 10–30 requests/minute from one IP triggers rate limiting
- User-agent detection: Default scraper user agents (Python-requests, Scrapy) are blocked immediately
- Behavioral patterns: No mouse movements, perfect timing intervals, no cookie acceptance
- IP reputation: Known datacenter IP ranges are pre-blocked by services like Cloudflare and Akamai
Proxy Solutions by Use Case
| Use Case | Recommended Proxy Type | Why | |----------|----------------------|-----| | High-speed crawling of low-protection sites | Datacenter proxies | Fast, low cost, high throughput | | Scraping e-commerce / protected sites | Rotating residential proxies | Real ISP IPs, low block rate | | Social media / account-based scraping | Private proxies | Dedicated IP per account | | Any protocol (HTTP + HTTPS + UDP) | SOCKS5 proxies | Full protocol support |
Rotation Strategies
Per-request rotation: Every HTTP request uses a different IP from the proxy pool. Ideal for scraping search results, product listings, and public APIs where no session state is needed.
Per-session rotation: The same IP is maintained for a sequence of requests (browsing a multi-page checkout flow, navigating a logged-in account). New IP assigned on each new session.
Time-based rotation: IPs rotate on a fixed interval (e.g., every 60 seconds). Useful for monitoring tasks that check the same URL repeatedly.
Top Web Scraping Libraries Compared
| Library | Language | Type | Best For | |---------|----------|------|----------| | Beautiful Soup 4 | Python | HTML parser | Simple static pages | | Scrapy | Python | Full framework | Large-scale crawl+scrape | | Requests-HTML | Python | HTTP + JS | Semi-dynamic pages | | Playwright | Python/Node.js/Java | Headless browser | JavaScript-heavy SPAs | | Puppeteer | Node.js | Headless Chrome | Google ecosystem, dynamic | | Selenium | Multi-language | Browser automation | Legacy, multi-browser | | Cheerio | Node.js | HTML parser | Fast, jQuery-style parsing | | Colly | Go | HTTP framework | High-performance crawling |
A Practical Web Scraping Example (Python + Beautiful Soup)
import requests
from bs4 import BeautifulSoup
import csv
# Configure proxy rotation (LimeProxies)
proxies = {
"http": "http://user:pass@proxy.limeproxies.com:8000",
"https": "http://user:pass@proxy.limeproxies.com:8000"
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
}
url = "https://example-store.com/products"
response = requests.get(url, proxies=proxies, headers=headers, timeout=10)
soup = BeautifulSoup(response.text, "html.parser")
products = []
for item in soup.select(".product-card"):
name = item.select_one(".product-name").text.strip()
price = item.select_one(".price").text.strip()
products.append({"name": name, "price": price})
# Save to CSV
with open("products.csv", "w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=["name", "price"])
writer.writeheader()
writer.writerows(products)
print(f"Scraped {len(products)} products")
For JavaScript-rendered pages, replace requests.get() with a Playwright page fetch.
Key Takeaways
- Crawling discovers URLs; scraping extracts data — they are complementary, not competing techniques
- Most production data pipelines use crawling first (to find pages) then scraping (to extract data from them)
- JavaScript-rendered pages require headless browsers (Puppeteer/Playwright) — simple HTTP scrapers will get empty responses
- At scale, rotating proxies are essential for both crawling and scraping to avoid IP blocks
- Always check
robots.txtand the site's Terms of Service before deploying scrapers - Residential proxies with rotation have the lowest block rates for scraping protected sites; datacenter proxies offer the best throughput for high-volume, low-protection targets
Post Quick Links
Jump straight to the section of the post you want to read:


About the author
LimeProxies Team
Related Articles
Datacenter vs Residential Proxies: Which Should You Choose in 2026?
Datacenter proxies are faster and cheaper for most tasks. Residential proxies handle heavily bot-protected sites. This guide breaks down every difference so you pick the right type — and avoid overpaying.
How to Use Proxies for E-Commerce Price Monitoring in 2026
Proxies are the backbone of reliable e-commerce price monitoring. Discover how to track competitor prices at scale, beat anti-bot systems, monitor geo-specific pricing, and build a full price intelligence stack in 2026.
Web Scraping With Proxies: The Complete Guide for 2026
Web scraping with proxies lets developers and businesses collect data at scale without IP bans or rate limits. This complete 2026 guide covers Python setup, proxy rotation, tool comparisons, anti-bot tactics, and ethical best practices.