

The rate of growth of data and information on the internet is an exponential one, and so is the number of searches that Google receives. Searches on google range from reviews about products and places, to finding out general information about something. No matter the information you seek, it is already available on the internet. The only problem you will face when it comes to retrieving data from the internet is that it is not readily present in a useable format. Most of it is present in an unstructured format (HTML format) and so cannot be downloaded. In order to bypass this barrier and get your hands on any type of data you need, you need to have knowledge of web scraping and here, you will learn web scraping with R.
This article will be particularly useful for data scientists because the knowledge will open up a world of limitless possibilities. Learning web scraping takes away whatever limit you may have to accessing data and you can get whatever you need easily.
What Is Web Scraping?
Web scraping is the process of converting the unstructured data (HTML tags) present on the internet to the structured format which you can easily access and make use of. It is possible to perform web scraping in almost all the main languages, but in this article, we will focus on web scraping with R and the data in question will be of the most popular feature films of 2016 from the IMDb website.
Interesting Read : Top 10 Web Scraping Techniques
The data that will be used are a number of features from 100 popular feature films from 2016. You will also be exposed to common problems you may encounter during web scraping with R due to inconsistency in the website code and how they can be solved.
Why Do We Need Web Scraping?
Web scraping is a technique that provides you with endless possibilities as long as data retrieval is concerned. Applications of web scraping include the following:
- Scraping movie rating data so as to create engines for movie recommendation
- Scraping text data from sources like Wikipedia to make NLP based systems or training deep learning models for tasks like recognizing a topic from a given text
- Scraping image data from websites to train models for image classification
- Scraping social media websites for data to perform task sentiment analysis, opinion mining and others
- Scraping product reviews and feedbacks from users on e-commerce sites like Amazon, Flipkart, etc.
Interesting Read : 5 Best languages for web scraping
Ways to Scrape Data
Web scraping can be done in a number of ways, but some of the most popular techniques are mentioned here. These include;
- Human copy-paste: this method involves web users themselves analyzing data firsthand and copying to local storage. It is slow but very efficient in scraping data from the web
- Text pattern matching: this is another simple yet powerful method of web scraping. It involves the use of regular expression matching facilities of programming languages to extract information from the web
- API interface: websites like Facebook, Twitter, LinkedIn, etc. provide APIs which can be used for data retrieval in the prescribed format
- DOM parsing: the use of web browsers allows programs to retrieve dynamic content generated by client-side scripts. You can also parse web pages into a DOM tree depending on the programs that can retrieve parts of the pages.
In web scraping with R, we will make use of the DOM parsing method in this article and rely on CSS selectors of the webpage in finding the fields that contain the required information.
Prerequisites
The prerequisites of web scraping with R is divided into two groups:
- To get started with web scraping using R, you must first have a good knowledge of the R language. If you are a beginner or you want to sharpen your skill, you should take up a course on R and be grounded in it. The ‘rvest’ package in R by Hadley Wickham is what will be used in this article. Install the package before you proceed and if you haven’t done that already, follow this code to install it; install.packages(‘rvest’)
- Having good knowledge of HTML and CSS is an added advantage. If you are not good at them, you should take up online courses to improve your skills. Since the majority of a data scientist are not experts in HTML and CSS, we will make use of Selector Gadget, open-source software that is sufficient to carry our web scraping. Go to the selector gadget’s website and download the extension, following the instructions from the website. If you are using google chrome, you can access the extension from the extension bar at the top right hand of your screen.
Interesting Read : Step By Step Complete Guide to Web Scraping With Python
With this in use, you can select the parts of any website you want to access by clicking on the part of the website and you will get the relevant tags you need. This extension helps you proceed with web scraping even if you do not have knowledge of HTML and CSS. It is a way around learning them. But if you want to master web scraping you must have to learn them so you can better understand what is happening and appreciate it.
Web Scraping Using R
Now we will move on with web scraping the IMDb website for the 100 most popular feature films of 2016.
#loading the rvest package
Library(‘rvest’)
#specifying the url for the desired website to be scraped
url <- ‘http://www.imdb.com/search/title?count=100&release_date=2016,2016&title_type=feature’
#reading the HTML code from the website webpage <- read_html(url)
The following data will be scraped from the IMDb website:
- Rank: the rank of the selected film from 1 to 100 on the list of most popular feature films of 2016
- Title: the title of the specific feature film
- Description: the summary of the feature film’s storyline
- Runtime: the playtime of the feature film
- Genre: the genre of the selected feature film
- Rating: the feature film’s IMDb rating
- Metascore: the Metascore of the feature film on the IMDb website
- Votes: number of votes cast in favor of the feature film
- Gross earning in mil: the gross earnings in millions of the feature film
- Director: the main director of the feature film, or the first in a case where there are multiple directors
- Actor: the main actor of the feature film, or the first in a case where there are more than one
Here is a screenshot showing the arrangement of all the fields
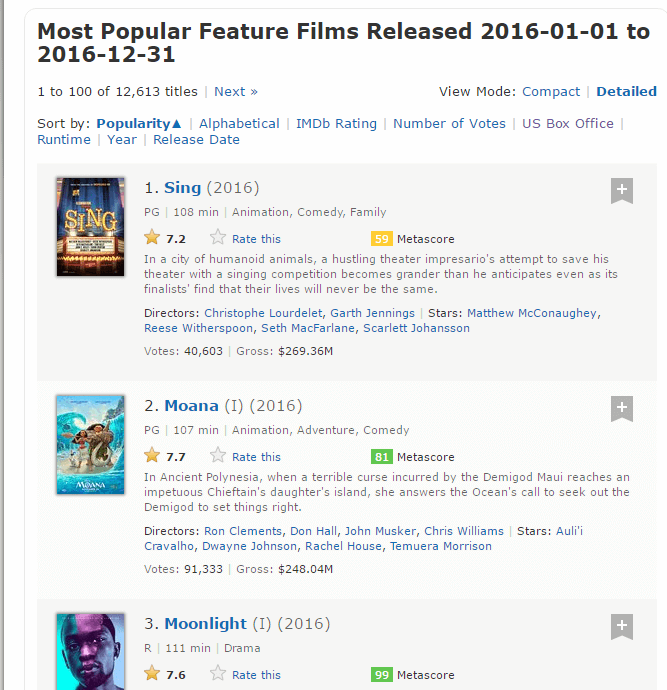
STEP 1: In the first step, we will start by scraping the rank field of feature films. To do this, we will make use of selector gadget to get the specific CSS selectors that enclose the rankings. To do this on your own, click the extension on your browser and select the rankings field.
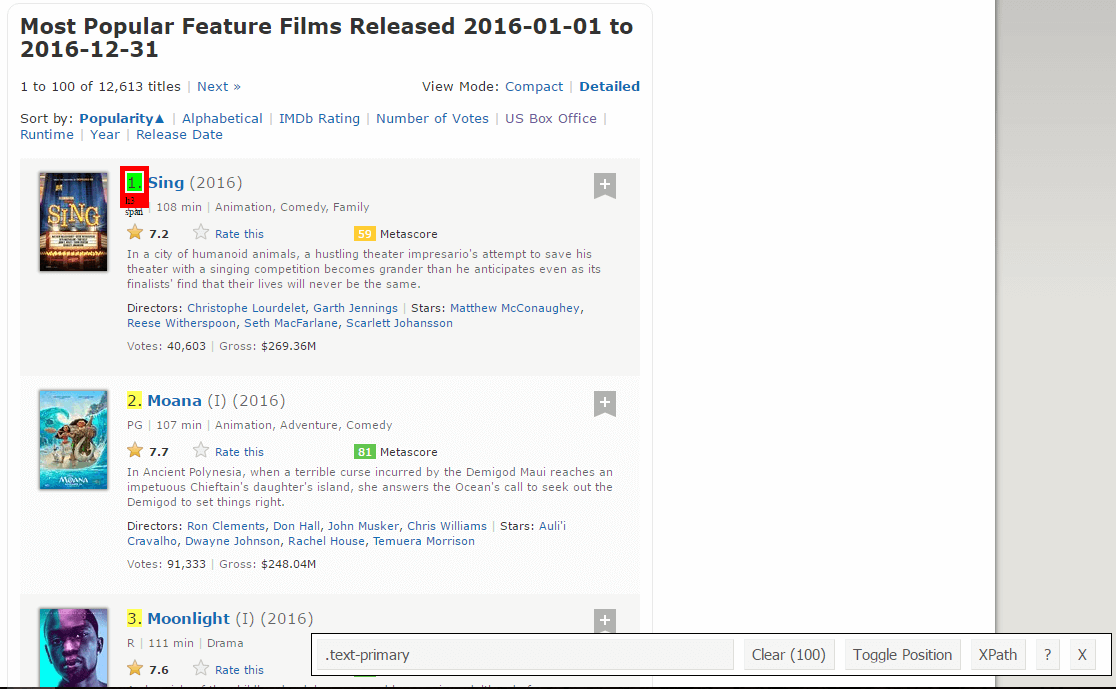
Make sure that you select all rankings. You can select more one by one in case you didn’t get them all, and you can deselect them by clicking on the selected section to confirm that only the highlighted sections are selected.
STEP 2: once you have cross-checked and confirmed that you have made the right selections, copy the corresponding CSS selector that you can view in the bottom center of your screen
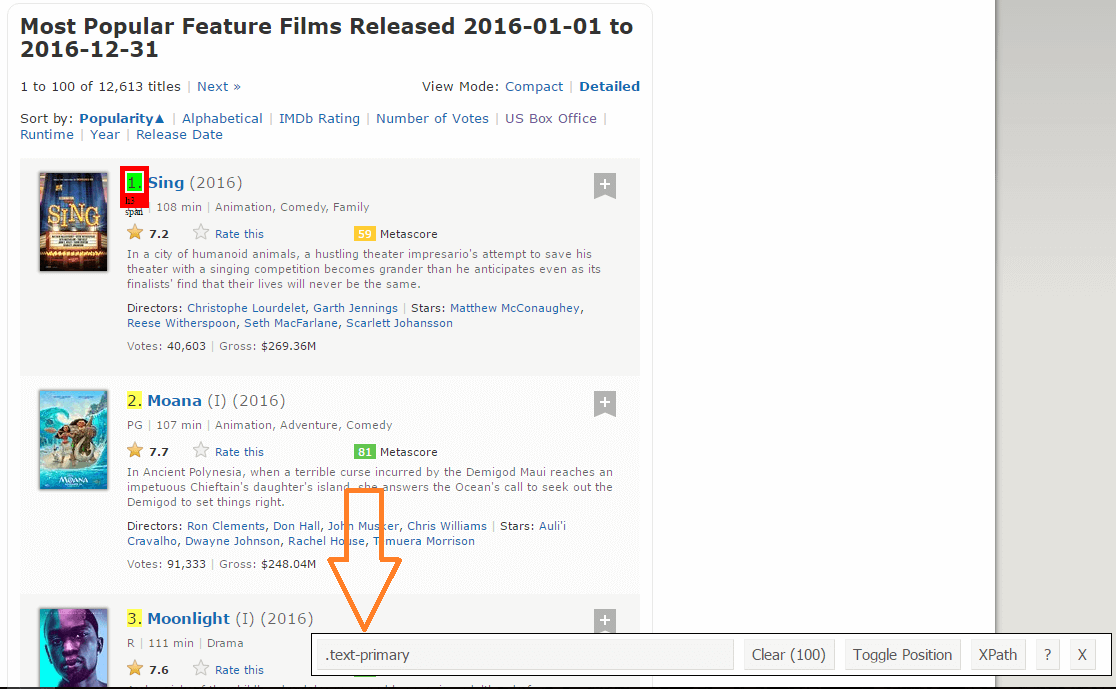
STEP 3: After confirming the CSS selector that contains all the rankings, use this R code to get them all;
#using CSS selectors to scrape the rankings section
rank_data_html <- html_nodes(webpage,’.text-primary’)
#converting the ranking data to text
rank_data <- html_text(rank_data_html)
#let's look at the rankings
head(rank_data)
[1] “1.” “2.” “3.” “4.” “5.” “6.”
STEP 4: once you get the data, check to be sure it is in the desired format. You can preprocess it to convert it to a numerical format.
#data-preprocessing: converting rankings to numerical
Rank_data<-as.numeric(rank_data)
#let's look at the rankings again
Head(rank_data)
[1] 1 2 3 4 5 6
STEP 5: you can now clear the selector section and select all film titles. Check to confirm that all the titles are selected. If you need to make additional selections or delete any, use your cursor and do the same.
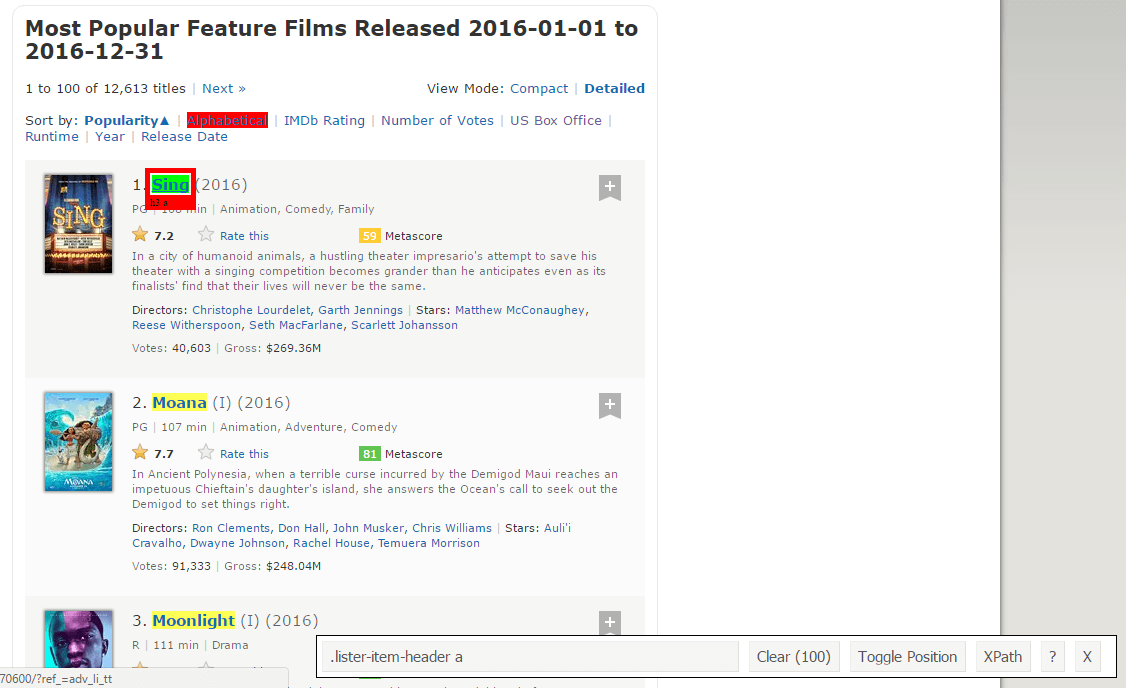
STEP 6: here you will make use of the corresponding CSS selector for the titles to scrap all titles using the following code:
#using CSS selectors to scrape the title section
Title_data_html <- html_nodes(webpage,’.lister-item-header a’)
#convert the title data to text
Title_data <- html_text(title_data_html)
#let's have a look at the title
Head(title_data)
[1] “sing” “Moana” “moonlight” “hacksaw ridge”
[5] “passengers” “trolls”
STEP 7: here, scraping will be done with the following code for the data: description, runtime, genre, rating, Metascore. Votes, gross earning in mil, director, and actor.
#using CSS selectors to scrape the description section
Description_data_html <- html_nodes(webpage,’.rtings-bar+ .text-muted’)
#converting the description data to text
Description_data <- html_text(description_data_html)
#let’s look at the description data
Head(description_data)
[1] “\nIn a city of humanoid animals, a hustling theater impresario’s attempt to save his theater with a singing competition becomes grander than he anticipates even as its finalists’ find that their lives will never be the same.”
[2] “\nIn Ancient Polynesia, when a terrible curse incurred by the Demigod Maui reaches an impetuous Chieftain’s daughter’s island, she answers the Ocean’ call to seek out the Demigod to set things right.”
[3] “\nA chronicle of the childhood, adolescence and burgeoning adulthood of a young, African-American, gay man growing up in a rough neighborhood of Miami.”
[4] “\nWWII American Army Medic Desmond T. Doss, who served during the Battle of Okinawa, refuses to kill people, and becomes the first man in American history to receive the Medal of Honor without firing a shot.”
[5] “nA spacecraft traveling to a distant colony planet and transporting thousands of people has a malfunction in its sleep chambers. As a result, two passengers are awakened 90 years early.”
[6] “\nAfter the Bergens invade Troll Village, Poppy, the happiest Troll ever born, and the curmudgeonly Branch set off on a journey to rescue her friends.”
#data-preprocessing: removing ‘\n’
Description_data<-gsub(“\n”,””,description_data)
#let's look at the description data again
Head(description_data)
[1] “In a city of humanoid animals, a hustling theater impresario’s attempt to save his theater with a singing competition becomes grander than he anticipates even as its finalists’ find that their lives will never be the same.”
[2] “In ancient Polynesia, when a terrible curse incurred by the Demigod Maui reaches an impetuous Chieftain’s daughter’s island, she answers the Ocean’s call to seek out the Demigod to set things right.”
[3] “A chronicle of the childhood, adolescence and burgeoning adulthood of a young, African-American, gay man growing up in a rough neighborhood of Miami.”
[4] “WWII American Army Medic Desmond T. Doss, who served during the Battle of Okinawa, refuses to kill people, and becomes the first man in American history to receive the Medal of Honor without firing a shot.”
[5] A spacecraft traveling to a distant colony planet and transporting thousands of people has a malfunction in its sleep chambers. As a result, two passengers are awakened 90 years early.”
[6] “After the Bergens invade Troll Village, Poppy, the happiest Troll ever born, and the curmudgeonly Branch set off on a journey to rescue her friends.”
#using CSS selectors to scrape the movie runtime section
Runtime_data_html <- html_nodes(webpage,’.text-muted .runtime’)
#converting the runtime data to text
Runtime_data <- html_text(runtime_data_html)
#Let's look at the runtime
Head(runtime_data)
[1] “108 min” “107 min” “111 min” “139 min” “116 min” “92 min”
#data-preprocessing: removing mins and converting it to numerical
Runtime_data<-gsub(“min”,””,runtime_data)
Runtime_data<-as.numeric(runtime_data)
#let's look at the runtime data again head(runtime_data)
[1] 1 2 3 4 5 6
#using CSS selectors to scrape the movie genre section
Genre_data <- html_text(genre_data_html)
#let's have a look at the runtime
Head(genre_data)
[1] “\nAnimation, Comedy, Family ”
[2] ‘\nAnimation, Adventure, Comedy “
[3] “\nDrama “
[4] “\nBiography< Drama, History “
[5] “\nAdventure, Drama, Romance “
[6] “\nAnimation, Adventure, Comedy “
#data-preprocessing: removing excess spaces
Genre_data<-gsub(“ “,””,genre_data)
#with only the first genre of each movie
Genre_data<-gsub(“,.*”,””,genre_data)
#converting each genre from text to factor
Genre_data<-as.factor(genre_data)
#let's now have another look at the genre data
Head(genre_data)
[1] Animation Animation Drama Biography Adventure Animation
10 Levels: Action Adventure Animation Biography Comedy Crime Drama… Thriller
#using CSS selectors to scrape the IMDB rating section
Rating_data_html <- html_nodes(webpage,’.ratings-imdb-rating strong’ )
#converting the ratings data to text
Rating_data <- html_text(rating_data_html)
#let’s look at the ratings
Head(rating_data)
[1] “7.2” “7.7” “7.6” “8.2” “7.0” “6.5”
#data-ppreprocessing: converting ratings to numerical
Rating_data<-as.numeric(rating_data)
#Let’s now have another look at the rating data
Head(rating_data)
[1] 7.2 7.7 7.6 8.2 7.0 6.5
#Using CSS selectors to scrape the votes section
votes_data_html <- html_nodes(webpage,'.sort-num_votes-visible span:nth-child(2)')
#Converting the votes data to text
votes_data <- html_text(votes_data_html)
#Let's take a look at the votes data
head(votes_data)
[1] "40,603" "91,333" "112,609" "177,229" "148,467" "32,497"
#Data-Preprocessing: removing commas
votes_data<-gsub(",","",votes_data)
#Data-Preprocessing: converting votes to numerical
votes_data<-as.numeric(votes_data)
#Let's now have another look at the votes data
head(votes_data)
[1] 40603 91333 112609 177229 148467 32497
#Using CSS selectors to scrape the directors section
directors_data_html <- html_nodes(webpage,'.text-muted+ p a:nth-child(1)')
#Converting the directors data to text
directors_data <- html_text(directors_data_html)
#Let's take a look at the directors data
head(directors_data)
[1] "Christophe Lourdelet" "Ron Clements" "Barry Jenkins"
[4] "Mel Gibson" "Morten Tyldum" "Walt Dohrn"
#Data-Preprocessing: converting directors data into factors
directors_data<-as.factor(directors_data)
#Using CSS selectors to scrape the actors section
actors_data_html <- html_nodes(webpage,'.lister-item-content .ghost+ a')
#Converting the gross actors data to text
actors_data <- html_text(actors_data_html)
#Let's now have a look at the actors data
head(actors_data)
[1] "Matthew McConaughey" "Auli'i Cravalho" "Mahershala Ali"
[4] "Andrew Garfield" "Jennifer Lawrence" "Anna Kendrick"
#Data-Preprocessing: converting actors data into factors
actors_data<-as.factor(actors_data)
Now observe closely what happens when the same process is repeated or Metascore data
#Using CSS selectors to scrape the metascore section
metascore_data_html <- html_nodes(webpage,'.metascore')
#Converting the runtime data to text
metascore_data <- html_text(metascore_data_html)
#Let's take a look at the metascore
data head(metascore_data)
[1] "59 " "81 " "99 " "71 " "41 "
[6] "56 "
#Data-Preprocessing: removing extra space in metascore
metascore_data<-gsub(" ","",metascore_data)
#Lets check the length of metascore data
length(metascore_data)
[1] 96
STEP 8: the metascore data has a length of 96, but the number of movies we are scraping for data is 100. This difference is due to the fact that 4 mobies do not have the respective metascore fields.
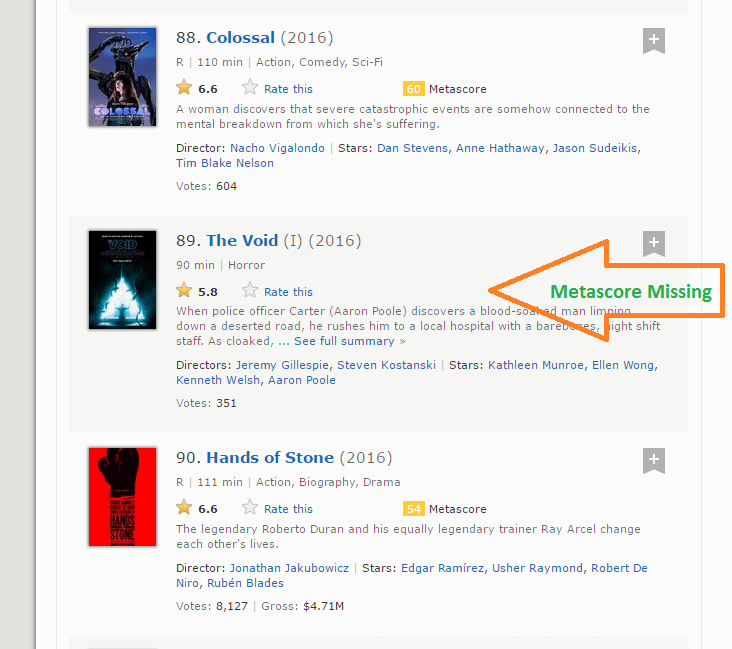
STEP 9: This step involves a practical situation you may face while scraping from a website. Adding NA’s to last 4 entries will map out NA as the Metascore for movies, rounding up the Metascore data from 96 to 100. In reality, data will still be missing for the 4 movies though. After a thorough inspection, Metascore was found to be missing for movies 39, 73, 80, and 89. To get around this problem, follow this function
for (i in c(39,73,80,89)){
a<-metascore_data[1:(i-1)]
b<-metascore_data[i:length(metascore_data)]
metascore_data<-append(a,list("NA"))
metascore_data<-append(metascore_data,b)
}
#Data-Preprocessing: converting metascore to numerical
metascore_data<-as.numeric(metascore_data)
#Let's have another look at length of the metascore data
length(metascore_data)
[1] 100
#Let's look at summary statistics
summary(metascore_data)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
23.00 47.00 60.00 60.22 74.00 99.00 4
STEP 10: the process is the same for the gross variable which stands for the gross earnings of the movie in millions. The same solution applies here.
#Using CSS selectors to scrape the gross revenue section
gross_data_html <- html_nodes(webpage,'.ghost~ .text-muted+ span')
#Converting the gross revenue data to text
gross_data <- html_text(gross_data_html)
#Let's take a look at the votes data
head(gross_data)
[1] "$269.36M" "$248.04M" "$27.50M" "$67.12M" "$99.47M" "$153.67M"
#Data-Preprocessing: removing '$' and 'M' signs
gross_data<-gsub("M","",gross_data)
gross_data<-substring(gross_data,2,6)
#Let's check the length of gross data
length(gross_data)
[1] 86
#Filling missing entries with NA
for (i in c(17,39,49,52,57,64,66,73,76,77,80,87,88,89)){
a<-gross_data[1:(i-1)]
b<-gross_data[i:length(gross_data)]
gross_data<-append(a,list("NA"))
gross_data<-append(gross_data,b)
}
#Data-Preprocessing: converting gross to numerical
gross_data<-as.numeric(gross_data)
#Let's take another look at the length of gross data
length(gross_data)
[1] 100
summary(gross_data)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.08 15.52 54.69 96.91 119.50 530.70 14
STEP 11: at this point you have successfully scraped all 11 features of 100 most popular feature films by IMDb in 2016. Now we will combine the data to create a dataframe and then inspect the resulting structure
#Combining all the lists to form a data frame
movies_df<-data.frame(Rank = rank_data, Title = title_data,
Description = description_data, Runtime = runtime_data,
Genre = genre_data, Rating = rating_data,
Metascore = metascore_data, Votes = votes_data, Gross_Earning_in_Mil = gross_data,
Director = directors_data, Actor = actors_data)
#Structure of the data frame
str(movies_df)
'data.frame': 100 obs. of 11 variables:
$ Rank : num 1 2 3 4 5 6 7 8 9 10 ...
$ Title : Factor w/ 99 levels "10 Cloverfield Lane",..: 66 53 54 32 58 93 8 43 97 7 ...
$ Description : Factor w/ 100 levels "19-year-old Billy Lynn is brought home for a victory tour after a harrowing Iraq battle. Through flashbacks the film shows what"| __truncated__,..: 57 59 3 100 21 33 90 14 13 97 ...
$ Runtime : num 108 107 111 139 116 92 115 128 111 116 ...
$ Genre : Factor w/ 10 levels "Action","Adventure",..: 3 3 7 4 2 3 1 5 5 7 ...
$ Rating : num 7.2 7.7 7.6 8.2 7 6.5 6.1 8.4 6.3 8 ...
$ Metascore : num 59 81 99 71 41 56 36 93 39 81 ...
$ Votes : num 40603 91333 112609 177229 148467 ...
$ Gross_Earning_in_Mil: num 269.3 248 27.5 67.1 99.5 ...
$ Director : Factor w/ 98 levels "Andrew Stanton",..: 17 80 9 64 67 95 56 19 49 28 ...
$ Actor : Factor w/ 86 levels "Aaron Eckhart",..: 59 7 56 5 42 6 64 71 86 3 ...
After completing your task of web scraping using R, you can now perform several tasks with the data you have access to. You can analyze the data, draw inferences from it, train machine learning models over the data and so on.


About the author
Rachael Chapman
A Complete Gamer and a Tech Geek. Brings out all her thoughts and Love in Writing Techie Blogs.
Related Articles
The Ultimate Guide to Chatbots for Lead Generation
Chatbot is currently used by most people on instant messaging application for better marketing strategy and to help the growth of business. Many are using chatbots for better customer service, increasing sales and improved marketing.
How to skyrocket your Marketing Effort?
Some decades ago, playing games was an act associated with childhood and immaturity. Nevertheless, regardless of one’s age, almost everyone you know has probably played a game or two.