
In this blog post, I’m sharing five lessons that every e-commerce data scientist must know about web scraping. If you’re new to web scraping, then this is exactly for you. For data scientists who have been doing this for some time, these web scraping insights should serve as a reminder of some key things that can make your web scraping activities effective and efficient.
Before we go into the details about each web scraping lessons listed above, let’s examine the role of web scraping in data science.
Is it needed? Should data scientist learn about web scraping?
DATA IS THE NEW OIL
Whether they are a startup or among the Forbes 500, every company needs data so they can formulate and improve their business strategies. 53% of companies have started adopting big data in 2017, a big leap from only 17% in 2015.
Data is the new oil, as what British mathematician Clive Humby declared way back in 2006:
https://twitter.com/stephenhuppert/status/1151336353235214337
This statement still rings true to some extent. Enterprises and even individuals rely on oil daily, making it a very precious and sought after commodity.Similarly, more and more companies are relying on data in several aspects of their businesses. From getting to know their customers better, developing products that are easy to market, setting up process automation, and also in setting their prices effectively.
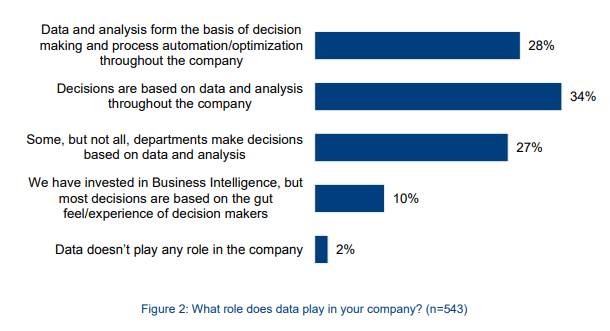
This chart from BARC Research entitled Big Data Use Cases shows the percentage of companies using data and analysis. As you can see, without data, businesses won’t gain the necessary knowledge and insights to improve their products and overall business strategies.
THERE’S DATA, AND THERE’S BIG DATA
I’m sure you know what big data is, but for discussion, let’s go ahead and define it before we proceed.
Big data simply refers to a huge volume of data that are gathered, stored, and analyzed using the latest technology. Because they are tremendously large, manually obtaining and analyzing them is a tedious, costly, and very ineffective process, which is why web scraping machines are widely used.
Like oil, data needs to be processed and applied for it to be truly useful. If they are not processed or analyzed, they remain useless. And if the insights gained from data analysis are not put into action or applied, then the costly and time-consuming act of data gathering in the first place is futile. To prove my point, here are some mind-blowing statistics on how big data can benefit businesses if used correctly:
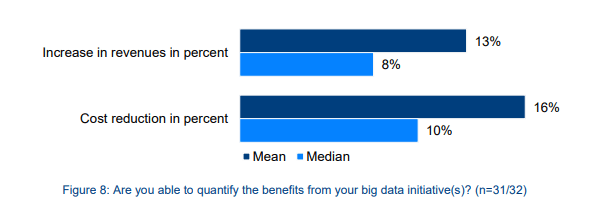
1 . Cost reduction: According to BARC Research, companies that use big data experienced a 10% (median value) to 16% (mean value) reduction in their cost. (You need to register and login to access this report.)
- Increase in profit: Still, according to the 2015 study made by BARC research, companies that use big data saw an 8% (median value) to 13% (mean value) increase in profit.
- More companies are using big data (location-wise): 28% of companies in North America and 16% in Europe had included big data in their business processes. 25% of companies are implementing big data as a pilot project. (BARC Research, 2015)
- More companies are using big data (industry-wise): 27% of companies in retail, 20% in the financial services industry, and 13% in manufacturing, services, and the public sector reported that big data is part of their business processes. (BARC Research, 2015)
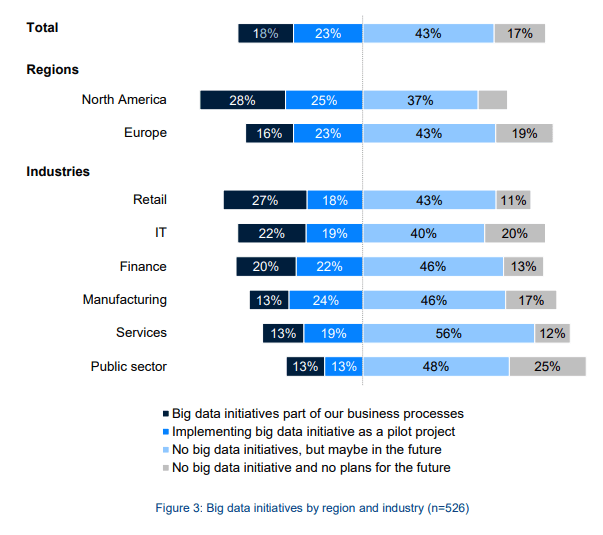
This chart from BARC Research shows the percentage of companies that are adopting and implementing big data, by location and by industry.
- Better control over operations: 54% of companies gained better control over their operations due to big data analysis. (BARC Research, 2015)
- A Better understanding of customers: 52% of companies learned more about their customers because of big data. (BARC Research, 2015)
- Improved strategic decision: 69% of companies said that their strategic decisions were better due to big data. (BARC Research, 2015)
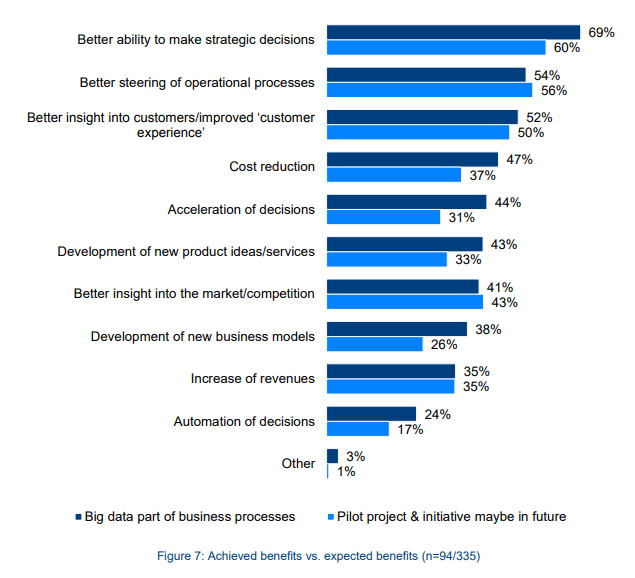
This chart shows the percentage of companies that experienced improvement in their business processes as a result of including big data in their business processes.
- Positive changes in core business practices: 30% of companies from different sectors reported a significant change in sales and marketing, research and development, and workplace management because of big data analytics. This is according to McKinsey Analytics’ Analytics Comes of Age report in January 2018.
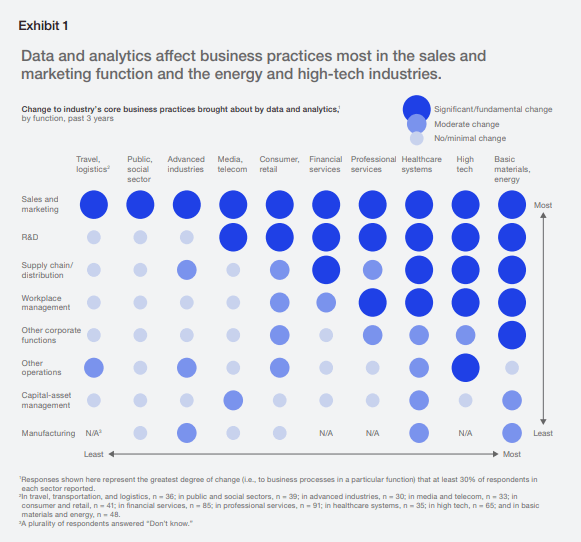
This chart shows the fundamental changes to core business practices caused by data and analytics, across different business sectors.
- Gain a competitive advantage: A study by Accenture revealed that 79% of business executives concede that companies that do not use big data will lose their competitive advantage and may even face business failure. 83% of them also said that they are adopting big data to gain an edge over the competition.
ARGUMENTS AGAINST “DATA IS THE NEW OIL” CONCEPT
The “Data is the new oil” concept, however, is not purely applicable to everything about big data, which is why it is faced with some criticisms. For instance, oil is still valuable when stored over periods. Data, however, becomes stale and useless when companies store them even for just a short period. Data should be time-sensitive and must be analyzed and used at once.
Still, this just means that data is a valuable resource, comparable to oil in the way companies seek it.
SHOULD DATA SCIENTISTS LEARN WEB SCRAPING?
Given these significant shifts towards big data in almost every industry as evidenced by the statistics listed in the previous section, data scientists must also adapt and learn how to access and obtain these data. Otherwise two things can happen:
Either the company you’re working for will get left behind by the competition, or;
You will lag behind other data scientists.
We already pointed out the benefits of using big data in the previous section, with statistics to back it up. Big data can only be gained through web scraping since doing it manually will be costly, labour-intensive, time-consuming and ultimately, ineffective.
The second point is also clear: Data scientists who don’t learn how to scrape the web can be at a disadvantage. This may be harsh, but it’s the reality. Forbes had cited a study by IBM that predicts the demand for data scientists to increase by 28% in 2020. The same research study found out that the most remunerative skills that a data scientist should have are MapReduce, Machine Learning, Big Data, Apache Hadoop, and Apache Hive, among others. What’s noteworthy is that most of these in-demand skills are also essential in web scraping.
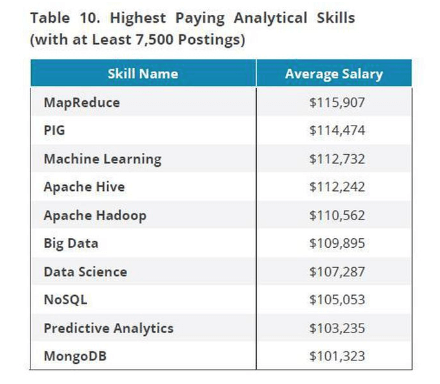
This table from Forbes shows the lucrative skills of data scientists and the average salaries per skills. The data was based on 7,500 job postings.
As an e-commerce data scientist, the industry you’re in greatly needs big data analytics and for this reason, you have to learn web scraping.
5 LESSONS EVERY E-COMMERCE DATA SCIENTIST MUST KNOW
#1 ALWAYS MONITOR THE QUALITY OF DATA
Web scraping becomes worthless if the quality of data is compromised. It is important to ensure that the data you gather is clean and accurate because important business decisions will depend on them. Imagine creating a pricing strategy based on erroneous and unreliable data. Maybe the websites being scraped are old versions and therefore do not contain the latest prices. Or perhaps your scraping machine is crawling the wrong websites/competitors. Instead of gaining competitive advantage, your company will lag behind and in the process, you will lose customers and profits.
With millions of datasets gathered each day, errors and inconsistencies can inevitably creep in. At the same time, because of the huge volume, it is difficult to manually monitor the accuracy of data and check for errors and inconsistencies. Besides, you may not notice immediately that there are errors in your spider. Despite this, you still have to monitor the quality of your data at all times, and the best way to do this is to automate the process.
QUALITY MONITORING WHILE DESIGNING THE SPIDER
When developing the spider, you have to regularly put in a QA process that will test the reliability of the extracted data. Peer reviews should be done every time changes to the code are made to ensure that the quality is not compromised.
QUALITY MONITORING SYSTEM
The best way to make sure that the data collected are accurate and clean is to set up an automated system that will ping you if there are errors and inconsistencies. There are several things to look out for that you should incorporate into your monitoring system, but the following are the most crucial ones:
1 . Site changes: Spiders return errors when the target site had made several updates on their structure. Make sure that your monitoring tool checks for changes in the target sites and notify you if it detects such changes.
- Data validation errors: Since you can set and define each data item according to a particular pattern, you can also set your tool to check if the data gathered meets the requirement set. If not, then you or another team member should be notified so you can manually validate the error.
Inconsistency with the volume: The number of records your crawlers return mostly follows a pattern, so if there is an unusual spike or decline in this number, this signals that you are being given false information or that there are significant changes to target sites. It’s therefore important to develop a tool that can detect inconsistencies in the volume of records.
- Data variation errors: Websites might feed your crawler false information as part of their anti-bot measures. Because of this, a website might return different data of the same product from the website’s other versions.
For example, a website selling cosmetic products have different versions of its site depending on the region — one for North America, another website version for Asia, and another website version for Europe. The company’s crown puller which is its lipstick line should have the same weight and dimensions across all website versions, but their anti-bot mechanism is feeding your crawler with varying data. Cases like this are rampant, so your monitoring tool should be able to detect this.
#2 ANTI-BOT MEASURES ARE BECOMING ADVANCED
With 52% of the overall web traffic coming from bots, and 29% of which are from bad or harmful bots, it’s understandable that the vast majority of websites are putting up measures to counter bot traffic. Yes, there are good and bad bots. Good or helper bots are welcome, and your website crawler is among the helper bots. On the other hand, bad bots are used by cybercriminals to carry out DDoS attacks on websites. Good bots crawl websites, while bad bots hack them.
How can websites distinguish traffic between good and bad bots then? To put bluntly, they can’t, so they are left with no choice but to treat all bots the same, regardless if they are harmful or helper bots. And for this reason, websites put up anti-bot measures that block out both good and bad bots.
COMMON ANTI-BOT MEASURES
Most websites ban bots through IP banning and filtering out non-human behaviour. When they detect that a specific IP address is sending too many requests over a short period, they automatically ban that IP address.
It’s not easy to define the exact human behaviour when it comes to requests sent to websites, but we can use a certain logic. If a person a website, he will see different pages and links, and will probably open as few as 5 to as many as 10 pages in another window. Let’s say in one minute, the person had made 10 requests. However, those requests were done with pauses in between them as the person scans or read each page.
In one hour, a person can make 300 to 600 requests. If I were the publisher or manager of a website, I’d set my bot detection tool to flag IP addresses that make more than 600 requests in one hour.
For larger websites like Amazon, more advanced and sophisticated methods are being used. Tools like Incapsula and Distil Networks make data extraction very difficult.
PROXIES TO EVADE IP BANNING
Since most websites set rate limits per IP, the only logical solution is to use proxies so you can distribute your requests over to different IP addresses. If your crawler can process 100,000 requests in one hour, you need around 200 proxies so each IP address will not go over the 600 requests threshold.
Of course, this is purely an assumption since we will never know how a website limits bot traffic if we don’t look at its code.
We have several resources you can consume to get to know more about proxies:
What are proxies and how they work?
What is a proxy and how it can help you?
How to choose between residential IPs and datacenter IPs.
#3 WEBSITE UPDATES HAPPEN AND THEY WILL BREAK YOUR SPIDERS
As I mentioned in the section about monitoring the data quality, websites often make structural changes, and these updates will break your spiders. Errors will occur and if you are not vigilant, the data you gather will be erroneous. It’s important to develop a quality monitoring tool that can detect website structural changes and notify you about these changes. Aside from this, keep in mind to check your code every month or two to make sure that they are still extracting data from the correct pages and websites.
Another issue you need to be aware of is the prevalence of websites that have sloppy or spaghetti codes. Your spiders will break when these target sites remove a product and on their 404 error handler, they begin sending 200 response codes instead.
#4 FOCUS ON CRAWLING EFFICIENCY
When you are competing in a track and field event, you don’t want to wear anything heavy which can slow you down. Most athletes wear light singlets over spandex shorts and lightweight sprint shoes. All of these ensure that you run efficiently, with no unnecessary weight on you.
The same thing goes for your crawling infrastructure. The more requests, the slower the data extraction will be. The goal is to gather big data with the most minimal number of requests so the crawling pace is fast and efficient.
What you can do to ensure crawling efficiency is to minimize the use of headless browsers such as Zombie JS, Puppeteer, and Headless Chrome. When you use headless browsers to render javascript, you use up a lot of resources, and your crawling speed will suffer.
As much as possible, do not request to access every individual page of an e-commerce site. If the data you need is on the shelf page, then don’t make additional requests. The information you need is almost always there anyway — price, product ratings, product names, descriptions, etc.
#5 DEVELOP A SCALABLE CRAWLING FACILITY
Scalability is an important characteristic that your crawling machine should have. You need a scalable crawler instead of one that only loops requests regularly. We are talking about millions of data, and a crawler that only loops requests will not make its mark. If it takes three seconds to complete each request (from data detection to data extraction), then the crawler will only be capable of sending 28,800 requests per day. Even if you increase the speed to two seconds per request, that would still be only 43,200 requests in a day.
When you’re crawling at scale, this kind of crawler is insufficient. What you can do is to separate your product or data discovery spiders from your data extraction spiders.
1 . Product discovery spiders: The role of product or data discovery spiders is to detect appropriate product, locate their shelf and add the right links in a list for scraping.
- Product extraction spiders: The data extraction spiders will then look at the list of URLs to scrape and will extract the necessary data.
Instead of having one kind of spider looking for products and doing the data extraction, you will now have two sets of spiders, one of them is focused on data extraction.
TO WRAP UP
There you have it, the five things every e-commerce data scientist must know. From developing scalable and efficient crawling machines, using proxies to counter anti-bot measures, to creating a quality monitoring system and looking out for website structural upgrades, these lessons will hopefully make you into a better data scientist who is ready to face the demands of the e-commerce big data world in the coming years.
Even when Noah Gift, the founder of Pragmatic AI Labs, predicted that there will no longer be data science job titles by the year 2029, you can start getting ready and adapting to inevitable changes by learning about web scraping, big data analytics, and other hot skills.
Try to check also this web scraping guide for more learnings.
Gift further wrote, “Some future job titles that may take the place of a data scientist include machine learning engineer, data engineer, AI wrangler, AI communicator, AI product manager and AI architect. The only thing that is certain is change, and there are changes coming to data science. One way to be on top of this trend is to not only invest in data science and machine learning skills but to also embrace soft skills. Another way is to think about tasks that can be easily automated -- feature engineering, exploratory data analysis, trivial modeling -- and work on tasks that are harder to automate, like producing a machine learning system that increases key business metrics and produces revenue.”
Data will remain to be a very essential resource for companies in the years to come. It will remain to be comparable to oil in its usefulness and effectiveness when truly applied as a core business process.
As an e-commerce data scientist, you can more effectively and efficiently extract data from the web with the use of proxies. Limeproxies offer dedicated and private proxies that will enable you to scrape the web without the fear of getting blocked.
.
 .
.

About the author
Rachael Chapman
A Complete Gamer and a Tech Geek. Brings out all her thoughts and Love in Writing Techie Blogs.
Related Articles
How to Access Facebook Using A Proxy Server: Bypassing Restricted Access
A lot of people make use of Facebook and they do so for various reasons. Here is How to Access Facebook Using Facebook Proxy: Bypassing Restricted Access
How web scraping can help in automobiles?
Automobile industry is customer-oriented which is exactly why it depends on the preferences. Know the factors involved in web scraping for automobiles